
Last week updates
My patchset on dir-iterator and local clone was merged into pu.
:) And the problem with st_ino could be solved combining it with st_dev (I’m
still going to confirm if there’s anything else I should do, thought).
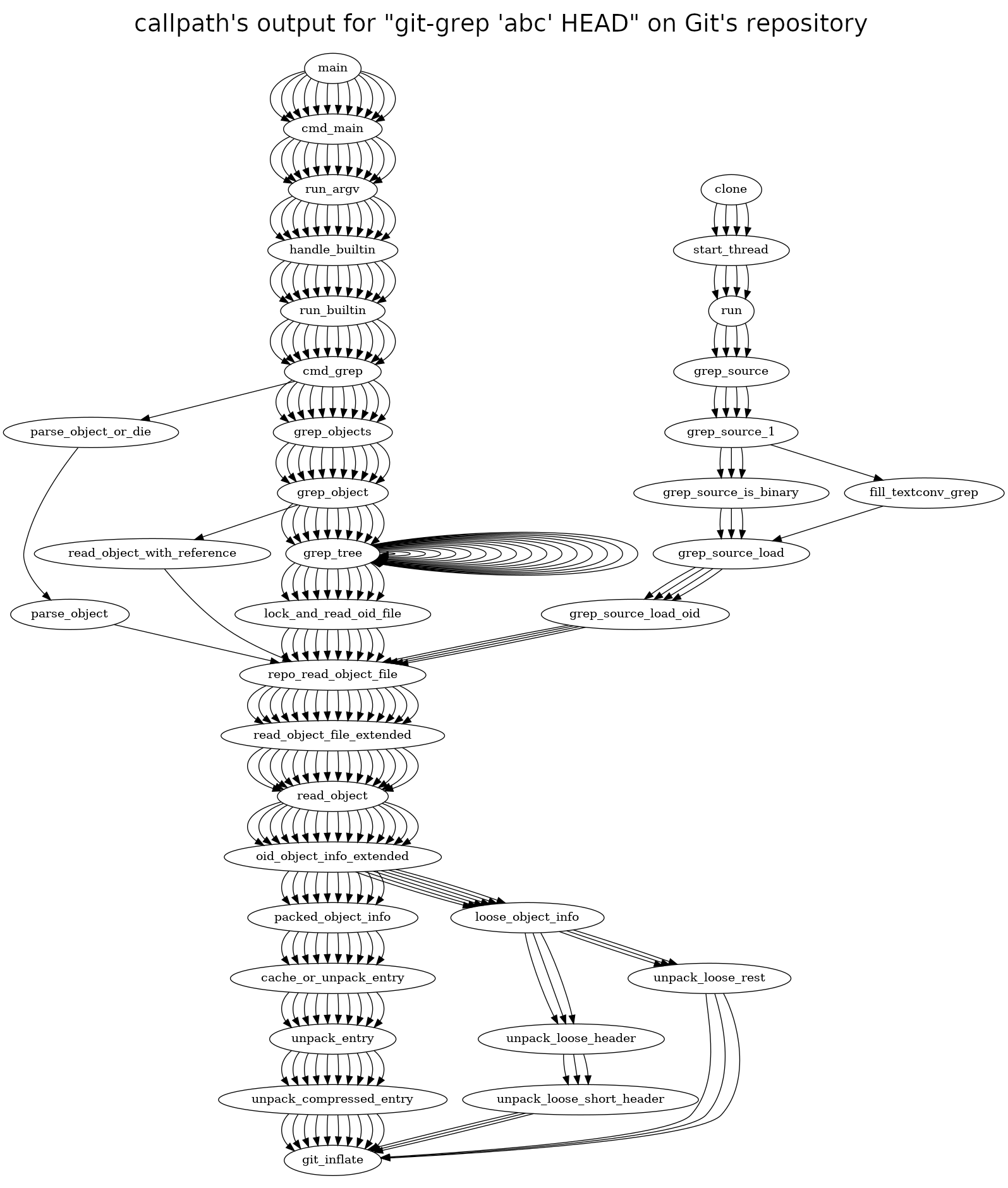
CallPath - paths in a call graph
Last week, I missed some tool which could tell me, given a function F, every path in a call graph that lead to F. I needed that, between other use cases, to ensure that locking a mutex at a function A, I’m guaranteed to still have it at another function B.
So, with Christian’s help, I coded a tool called callpath.
It executes a command in gdb, collects and parses its output and plots all the
paths to an specific function using dot. As you’ll see, callpath was used a
couple times throughout this post to validate some assumptions.
Parallel zlib inflation
We’ve already seen in my previous post that zlib inflation showed itself as the perfect candidate in the pack access code to be made parallel. But I was having some deadlock and SegFault errors when trying to implement it, last week. So I started over from scratch with the simplest idea possible (based on the previous ones). It goes like this:
1) Protect read_object_file_extended()
We know pack access is not thread safe, so let’s add a mutex protecting
read_object_file_extended(). This is git-grep’s only entry point to the pack
access code, so it is the only function we care, for now.
2) Remove git-grep read lock
Now that we have a “thread-safe” read_object_file_extended(), let’s remove
git-grep’s read lock. This is not as simple as it seems, thought, since the lock
not only protects object reading but also submodule and textconv operations. As
the idea is to start simple, thought, let’s ignore those two other critical
sections, leaving them unprotected, for now.
Ok, but two unprotected non-thread-safe sections seems a little dangerous,
right? Well, for the test cases I’m currently running, callpath shows that
these two sections are not even being executed, so we’re safe. But that’s
certainly something I’ll have to handle before the final version.
3) Perform zlib inflation in parallel
We know that git_inflate() is the function responsible for handling zlib
inflation. So if we can guarantee that the lock added at step 1 will be held by
a thread when it gets to git_inflate(), we can safely unlock it at the
beginning and re-lock at the end. That way, we could safely allow threads to
work at inflation in parallel! And indeed, as you can see
here, callpath
confirms git_inflate will only be reached (in my test cases) through
read_object_file_extended(), which holds the lock.
{kind=link}
Results
Ok, the idea per se is quite simple, the hardest part was debugging and confirming those safety issues about unlocking and re-locking. You can see a hacky implementation of it here.
Tests were performed greping the following regexes on gentoo (commit
161f8c8):
abcde[12]-E '(static|extern) \b(int|double)\b \*[A-Za-z]+'
And calculating the mean of 30 repetions taken before 2 warmup executions1:
Times on git-grep at gentoo repo
==============================
Threads 2
Regex 1 Regex 2
Original: 1.6958s 2.4638s
Parallel inflate: 0.9972s 2.2359s
Reduction: 41.20% 9.25%
Threads 8
Regex 1 Regex 2
Original: 1.8038s 1.9803s
Parallel inflate: 0.9593s 1.3033s
Reduction: 46.82% 34.19%
Ok, we can already see some good results, but Gentoo is a quite small repo. So
I also wanted to test with Linux and Chromium. But with them, I started to get
Segmentation fault, again! It always happens in the following call stack:
(most recent call first)
entry_equals()
find_entry_ptr()
hashmap_get()
get_delta_base_cache_entry()
unpack_entry()
cache_or_unpack_entry()
packed_object_info()
oid_object_info_extended()
read_object()
read_object_file_extended()
repo_read_object_file()
grep_source_load_oid()
grep_source_load()
grep_source_is_binary()
grep_source_1()
grep_source()
run()
start_thread()
clone()
And adding a new mutex responsible just for the delta_base_cache doesn’t
help at all…
Race conditions on delta_base_cache
I’m still trying to figure out the cause of this problem, but I have an educated guess based on what I’ve investigated so far. We can think of git-grep’s threads, regarding object reading, like this:
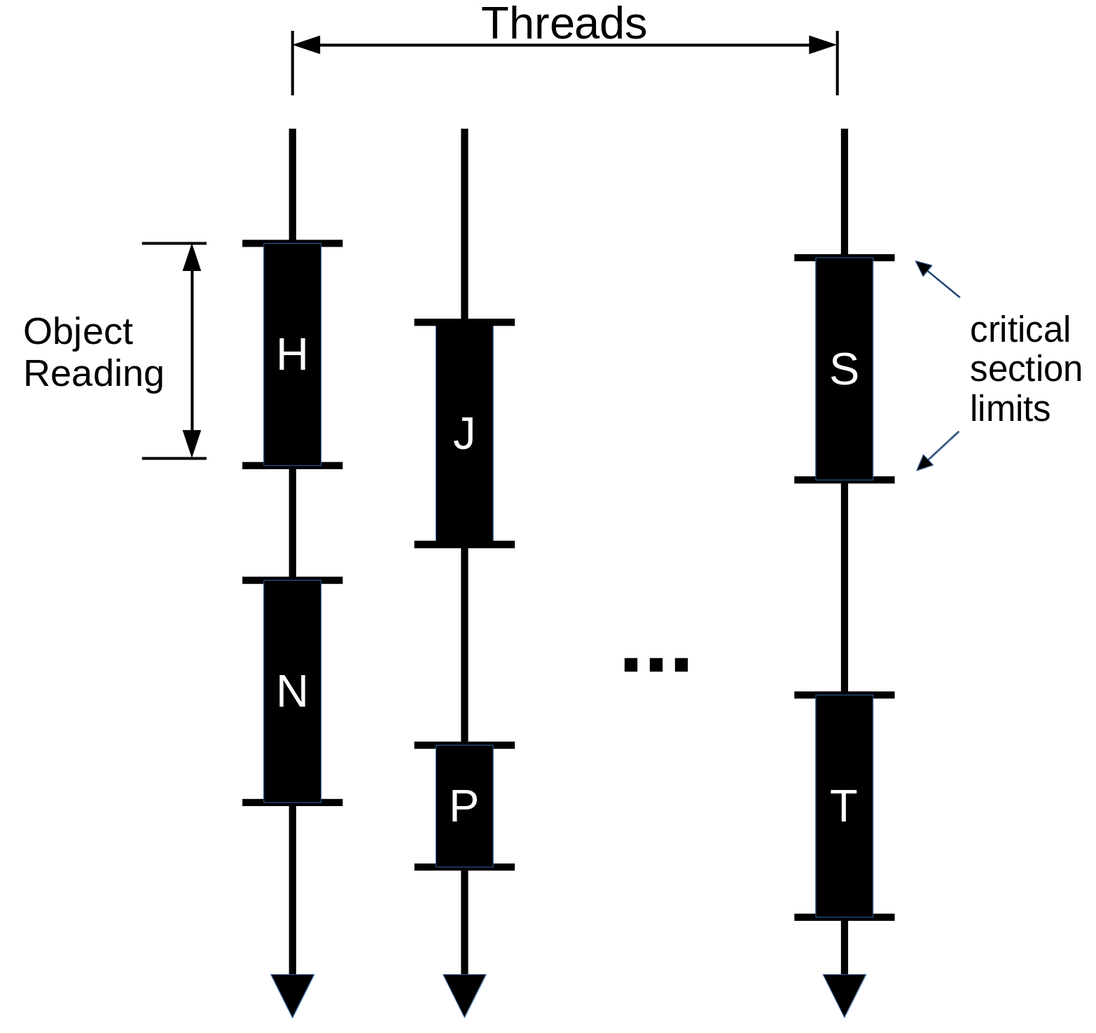
And the order in which these critical sections (H, N, S, ...) will be executed
doesn’t matter (remember they are serialized).
But when we break this critical sections, to allow parallel inflation, we end up with something like this:
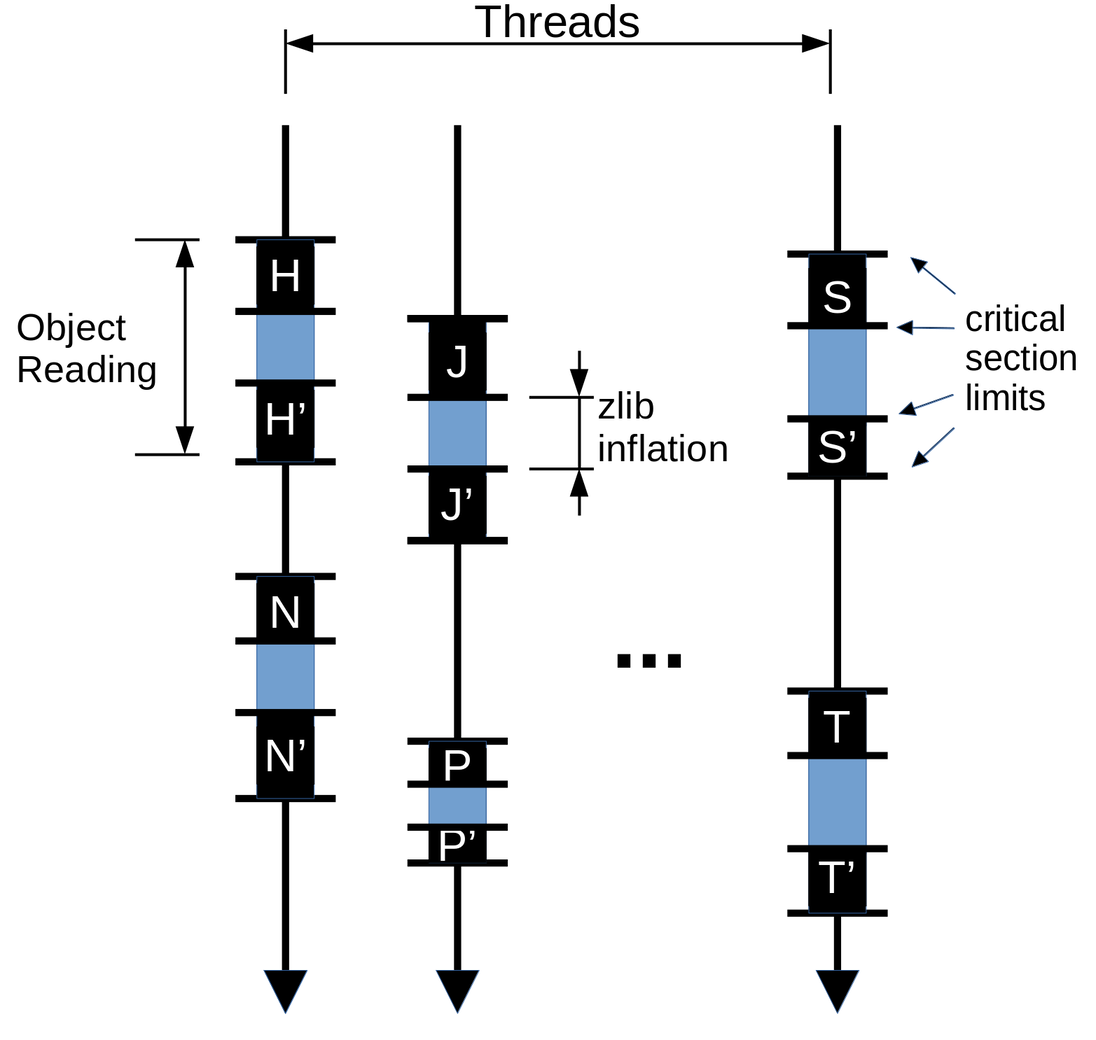
And at this time, there’s no guarantee that N' will be executed right after
N, for example. So we may have an order like this: N, S, S', N', .... And
now, S, may change a global variable which N' is already expecting to have a
certain value set by N. This may be the reason of the SegFaults when handling
the delta_base_cache.
It does make sense because if the cache is full when adding a new entry, it may
be necessary to remove the least recently used entry (or entries). So
intercalating N and N' with other critical sections may remove an entry
which N' expects to be present. And indeed, increasing
core.deltaBaseCacheLimit made the parallel-inflate version work on the Linux
repo, corroborating with this guess. But I’m not sure, yet, if that’s the case
and, if so, how we could prevent it from happening.
Next steps
- Continue investigating the
delta_base_cacheSegFaults; and how to avoid the problems with the execution order of critical sections (the intercalations). - Measure speedup on Linux and Chromium.
- Make the patch less hacky and protect the submodule and textconv operations, which were left behind.
- Try to refine the object reading locks to have more parallel work.
Footnotes
-
The output of each test was compared with a reference output for validation. ↩
Til next time,
Matheus